들어가며
지난 글에서는 LCP 7.6초라는 문제를 진단하고, 네 가지 방법을 비교해 S3 이벤트 기반 Lambda 비동기 처리 방식을 선택하기까지의 과정을 다뤘다.
이미지 최적화 파이프라인 구축기 (1) - 문제 진단과 방법 선택
들어가며이전에 정적 이미지 최적화 방식을 다룬 글을 작성한 적 있다. 이번에는 사용자가 업로드한 이미지를 최적화한 경험을 정리해보려 한다. 이번 글에서는 LCP 7.6초라는 수치를 발견하고,
sanghee01.tistory.com
이번 글에서는 실제로 어떻게 구현했는지를 다룬다. S3 이벤트 트리거 설정부터 Lambda 함수 구현, 원본과 최적화 버킷 분리 설계까지 순서대로 진행한다.
전체 파이프라인 구조
이미지 업로드부터 최적화 과정,사용자에게 이미지가 보이기까지의 전체 흐름을 먼저 간단히 짚고 넘어가자.
- 사용자가 이미지를 업로드하면, 백엔드로부터 발급받은 *Presigned URL을 통해 S3 원본 버킷에 직접 저장된다.
- 이 업로드 이벤트가 Lambda를 트리거하고, Lambda는 Sharp를 통해 이미지 최적화를 진행한 뒤 별도의 S3 최적화 버킷에 저장한다.
- 클라이언트는 최적화 버킷의 이미지를 먼저 시도하고, 실패 시 원본 버킷의 이미지로, 그마저도 실패하면 기본 이미지로 순차적으로 fallback된다.
*Presigned URL: 클라이언트가 백엔드 서버를 거치지 않고 S3에 직접 파일을 올릴 수 있도록 임시로 발급되는 인증 URL

S3 이벤트 트리거 설정
이미지 업로드 이후 최적화가 자동으로 실행되도록, S3 원본 버킷의 업로드 이벤트를 트리거로 Lambda 함수가 실행되도록 구성했다.
Lambda를 생성한 뒤, 다음과 같이 트리거 구성 과정을 진행했다.
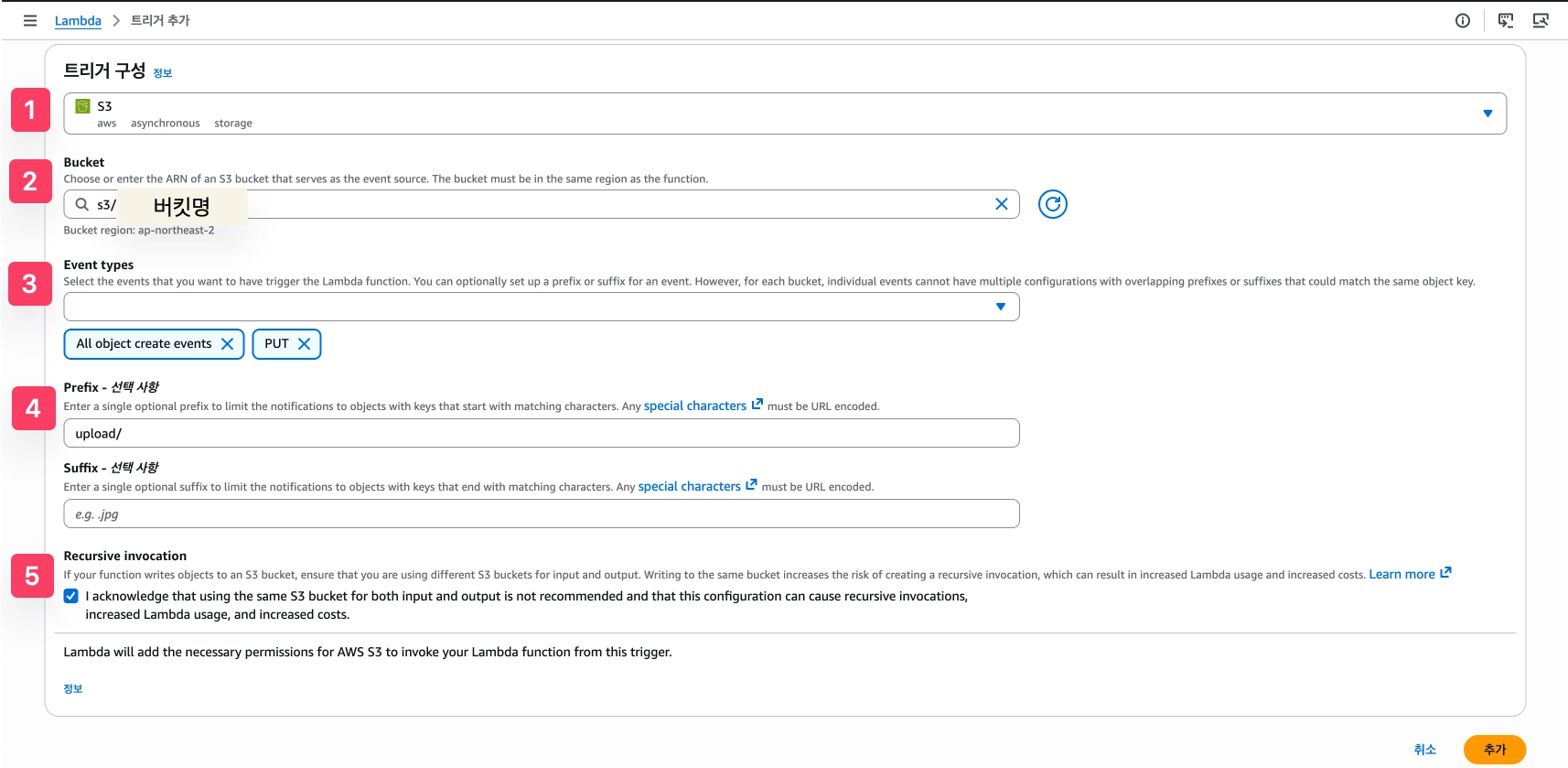
- (1), (2) Bucket: S3 원본 버킷 지정
- (3) Event type:
s3:ObjectCreated:\*— PUT을 포함한 모든 객체 생성 이벤트에 트리거 - (4) Prefix:
upload/— 원본 이미지가 저장되는 경로만 이벤트가 발생하도록 범위 제한- *모멘트 서비스는 원본 버킷은
upload/, 최적화본 저장 버킷은upload-resize/로 되어있다.
- *모멘트 서비스는 원본 버킷은
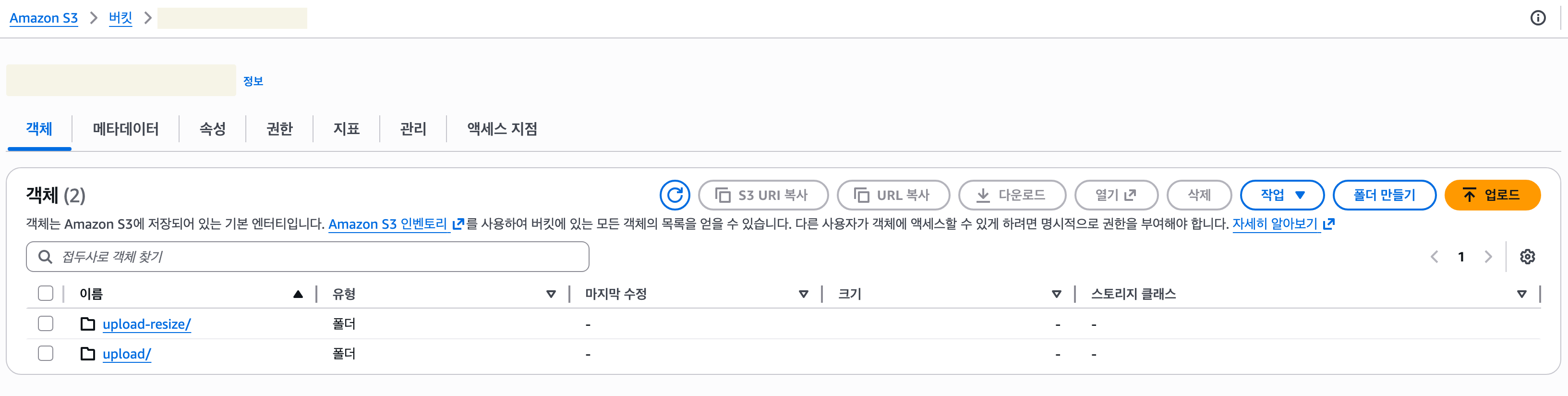
- (5) 입력과 출력 버킷을 분리하는걸 권장한다는 안내 문구이다. 인지했으면 체크하면 된다.
번역: 입력과 출력에 동일한 S3 버킷을 사용하는 것은 권장되지 않으며, 이러한 구성으로 인해 재귀 호출, Lambda 사용량 증가 및 비용 증가가 발생할 수 있음을 인지하고 있습니다.

이와 같은 설정으로 업로드 이벤트가 발생하는 순간 Lambda가 자동으로 실행되므로, 별도의 API 호출이나 수동 처리 없이 최적화가 비동기로 진행된다.
Lambda 함수 구현
Sharp 라이브러리
Lambda 함수 내부에서는 Node.js 환경에서 이미지 처리에 가장 널리 쓰이는 Sharp 라이브러리를 사용했다.
Sharp는 libvips 기반으로 동작해 처리 속도가 빠르고, 리사이즈·포맷 변환·품질 조정·메타데이터 제거를 하나의 체인으로 처리할 수 있다.
적용한 설정은 다음과 같다.
// 람다 코드 중 이미지 최적화 설정 부분
const output = await sharp(content_buffer)
.rotate() // EXIF orientation 기반 자동 회전 (메타데이터 제거 전 처리)
.resize(400, 400, { fit: "inside" }) // 서비스 최대 사용 크기 기준 리사이즈
.webp({ quality: 80 }) // WebP 변환 + 품질 80 (메타데이터는 Sharp 기본 동작으로 자동 제거)
.toBuffer(); // 처리된 이미지를 Lambda 컨테이너 메모리에 Buffer로 반환
각 메서드를 하나씩 알아보겠다.
Rotate - .rotate()
추후 설명할 예정이지만, 최적화 과정에서 이미지 메타데이터를 제거한다.
휴대폰 사진에는 EXIF의 Orientation 값이 있는데, 여기에는 회전 정보가 들어있다. 이 메타데이터를 제거하면 올바르지 않은 방향으로 이미지가 변환될 수 있다.
따라서 최적화 진행 전, .rotate()를 통해 EXIF의 Orientation 값 기반으로 이미지를 먼저 회전시켜야 정상적인 방향으로 변환될 수 있다.
실제로 해당 메서드를 넣기 전, 아래 왼쪽 게시글처럼 이미지가 엉뚱하게 회전돼서 보였다.

Resize - .resize(400, 400, { fit: "inside" })
이전 글에서 Lighthouse 분석을 했을 때, '화면에 필요한 크기보다 훨씬 큰 이미지가 그대로 전달되고 있다'는 내용이 있었고(아래 사진 2번 내용), 실제로 S3에 저장된 이미지가 원본 그대로였음을 확인했다.
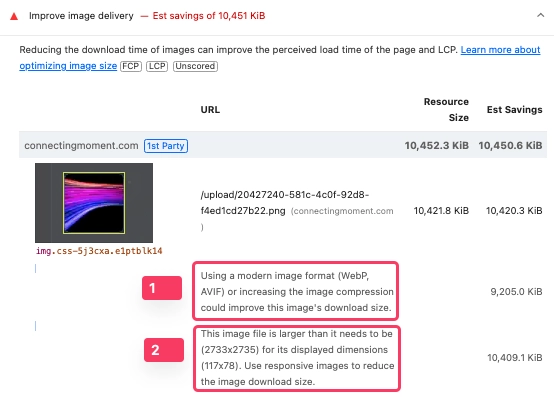
이를 반영해 서비스 최대 사용 크기를 기준으로 리사이즈를 적용했다.
서비스에서 이미지가 사용되는 가장 큰 화면인 확대 이미지 모달 기준으로 크기를 결정했다. 썸네일과 확대 모달 모두 400×400으로 충분했기 때문에, 하나의 최적화본으로 두 가지 용도를 커버할 수 있도록 이 크기를 기준으로 잡았다.
또한, fit: "inside" 옵션을 적용해 원본 비율을 유지하면서 400×400 안에 들어오도록 리사이즈했다. 이 옵션 없이 resize(400, 400)만 적용하면 원본 비율과 관계없이 강제로 정사각형으로 만들어 이미지가 찌그러질 수 있다.
WebP 변환과 압축도 설정 - .webp({ quality: 80 })
확장자를 WebP로 변환해 Lighthouse가 "최신 이미지 포맷 사용 시 다운로드 용량을 줄일 수 있다"고 제시한 개선 포인트를 반영했다. (아래 사진 1번 내용)

WebP는 무손실 압축과 손실 압축 모드를 모두 지원한다.
사용자가 업로드한 사진 이미지는 색 변화가 자연스럽고 세부 디테일이 많아, 손실 압축을 적용해도 사용자가 품질 저하를 인지하기 어렵고 용량 절감 효과가 크다. 따라서 손실 압축을 적용했다.
무손실 압축 vs 손실 압축
무손실 압축
- 데이터를 하나도 버리지 않고 압축. 압축을 풀면 원본과 완전히 동일하며, 파일 크기 감소 효과는 상대적으로 작다.
- .webp({ lossless: true }
손실 압축
- 사람 눈에 잘 안 보이는 데이터를 일부 버리면서 압축. 원본으로 되돌릴 수 없지만 파일 크기를 훨씬 많이 줄일 수 있다.
- .webp({ quality: 80 })
- Sharp에서 .webp({ quality: 80 })은 lossless: true를 명시하지 않았으므로 기본적으로 손실 압축 모드로 동작한다.
quality는 손실 압축 모드 안에서 "얼마나 버릴 것인가"를 조절하는 값이다.
quality 75~85 구간은 눈에 띄지 않는 수준의 품질 손실과 함께 상당한 파일 크기 감소를 제공하는 실용적인 최적점으로 알려져 있다. 이 범위 내에서 80을 선택했다.
만약 quality를 너무 낮게 주면 사진이 흐릿하게 보여져 오히려 사용자경험을 헤치게 될 수 있다.

메타데이터 제거
이미지에는 촬영 날짜, GPS 위치 정보 등이 EXIF 메타데이터로 포함될 수 있다. 서비스에서 필요하지 않은 정보일 뿐만 아니라, 다른 사용자가 이미지를 다운로드하면 이 정보가 그대로 노출되어 개인정보 보안 문제로 이어질 수 있다.
Sharp는 출력 시 별도 설정 없이 기본적으로 모든 메타데이터를 제거한다. (Sharp 공식 문서)
toBuffer() 는 최적화된 이미지를 Lambda 컨테이너 메모리에 Buffer 형태로 반환한다. 파일로 저장하지 않고 메모리에서 곧바로 S3에 업로드할 수 있어, 불필요한 디스크 I/O 없이 처리가 완료된다.
전체 코드
주석 설명과 함께 전체 코드를 첨부한다.
// AWS S3와 통신하기 위한 SDK 라이브러리
const { S3Client, GetObjectCommand, PutObjectCommand } = require("@aws-sdk/client-s3");
// 이미지 처리 라이브러리
const sharp = require("sharp");
// 스트림 데이터를 Buffer(바이트 배열)로 변환하기 위한 유틸리티
const { buffer } = require("stream/consumers");
// S3 클라이언트 초기화 (서울 리전)
const s3 = new S3Client({ region: "ap-northeast-2" });
// Lambda 함수 진입점 — S3 이벤트 발생 시 자동으로 실행됨
exports.handler = async (event) => {
// S3는 한 번에 여러 이벤트를 묶어 전달할 수 있어 반복문으로 처리
for (const record of event.Records ?? []) {
// 이벤트에서 버킷명과 파일 경로(key) 추출
const bucket = record.s3.bucket.name;
const key = decodeURIComponent(record.s3.object.key.replace(/\+/g, " "));
// upload-resize/ 경로(최적화 버킷)에서 발생한 이벤트는 건너뜀
// → 최적화본 저장 시 다시 Lambda가 트리거되는 재귀 호출 방지
if (key.startsWith("upload-resize/")) continue;
// 원본 파일명에서 확장자를 제거하고 .webp로 변환한 저장 경로 생성
// 예) upload/abc.jpg → upload-resize/abc.webp
const fileName = key.split("/").pop();
const baseFileName = fileName.split(".").slice(0, -1).join(".");
const dstKey = `upload-resize/${baseFileName}.webp`;
try {
// S3에서 원본 이미지 읽기
const res = await s3.send(new GetObjectCommand({ Bucket: bucket, Key: key }));
// 스트림 데이터를 Buffer로 변환 (Sharp가 처리할 수 있는 형태)
const content_buffer = await buffer(res.Body);
// 이미지 최적화
const output = await sharp(content_buffer)
.rotate() // EXIF orientation 기반 자동 회전 (메타데이터 제거 전 처리)
.resize(400, 400, { fit: "inside" }) // 서비스 최대 사용 크기 기준 리사이즈
.webp({ quality: 80 }) // WebP 변환 + 품질 80
.toBuffer(); // 처리된 이미지를 Lambda 컨테이너 메모리에 Buffer로 반환
// 최적화본을 S3 최적화 버킷에 저장
await s3.send(
new PutObjectCommand({
Bucket: bucket,
Key: dstKey, // 저장 경로: upload-resize/파일명.webp
Body: output, // 최적화된 이미지 데이터
ContentType: "image/webp",
})
);
} catch (error) {
console.error("FAIL", { key, dstKey, errorName: error?.name, errorMessage: error?.message });
throw error;
}
}
};
원본/최적화 버킷 분리 설계
원본 이미지와 최적화본은 같은 버킷이 아닌 별도의 버킷에 분리해서 저장했다. 이유는 두 가지다.
재귀 트리거 방지
같은 버킷을 입력과 출력으로 함께 사용하면, 최적화본을 저장할 때 다시 S3 업로드 이벤트가 발생해 Lambda가 무한히 트리거되는 재귀 호출 문제가 생긴다. 버킷을 분리하면 이 문제를 구조적으로 차단할 수 있다.
앞서 S3 이벤트 트리거 설정에서 Prefix: upload/로 범위를 제한한 것도 같은 이유다. 혹시 같은 버킷을 써야 하는 상황이라면 Prefix 설정만으로도 재귀 호출을 막을 수 있지만, 우리 서비스는 구조적으로 더 명확하게 분리하는 방향을 택했다.
최적화 실패 시 원본 fallback
Lambda 처리가 실패하거나 최적화본이 아직 생성되지 않은 상황에서도, 원본 버킷에 이미지가 보존되어 있어 사용자에게 이미지를 보여줄 수 있다.
클라이언트의 useImageFallback 훅이 최적화 버킷 → 원본 버킷 → 기본 이미지 순서로 순차적으로 fallback 처리하도록 로직을 작성하였다.

결과
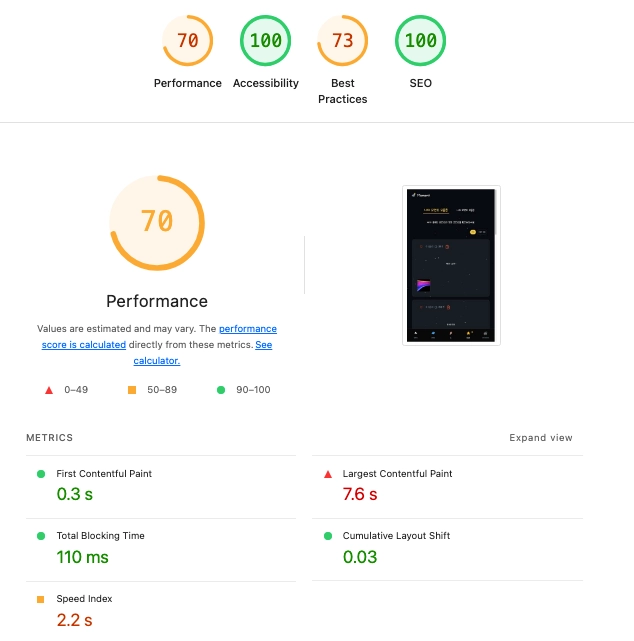
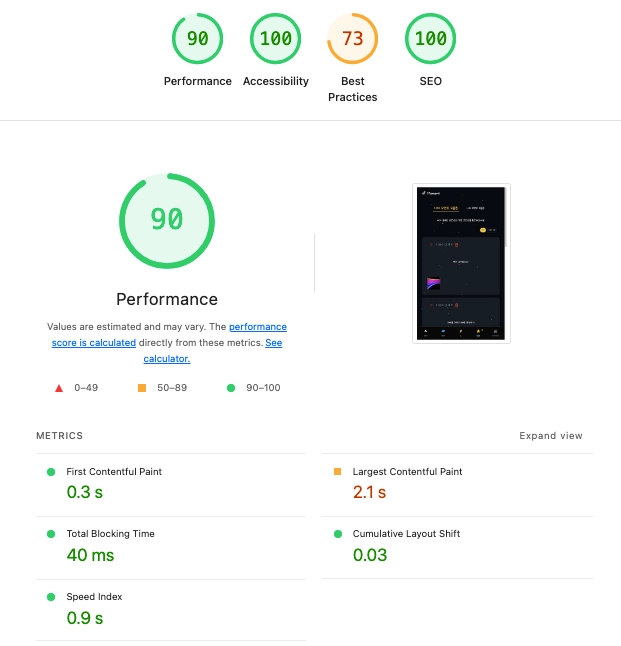
S3 이벤트 기반 Lambda 파이프라인 구축 후 Lighthouse를 다시 측정했다.
- LCP: 7.6초 → 2.1초 (Google Core Web Vitals 기준 '나쁨' → '좋음' 구간)
- Performance 점수: 70 → 90
LCP 2.5초 이하라는 Google의 좋은 사용자 경험 기준을 충족하게 됐다.
Network 탭에서도 변화가 뚜렷했다. 문제 상황에서 주요 병목으로 지목했던 이미지 리소스의 Content Download 시간이 632ms에서 0.52ms로 단축됐다.
전체 이미지 로드 시간도 702ms에서 15.71ms로 줄어, 이미지 다운로드 구간의 병목이 사실상 해소됐다.


사용자가 게시물을 탐색할 때 이미지가 이전 대비 거의 즉시 표시되어, 이전처럼 이미지를 기다려야 하는 상황이 많이 해소되었다.
또한 일회성 개선이 아니라, 사용자가 이미지를 업로드하면 자동으로 최적화본이 생성되는 구조를 마련했다는 점에서 운영 측면에서도 의미 있는 결과다.
마무리
이번 글에서는 S3 이벤트 트리거 설정부터 Lambda 함수 구현, 원본/최적화 버킷 분리 설계까지 파이프라인을 어떻게 구축했는지 다뤘다. 그 결과 LCP를 7.6초에서 2.1초로 단축하고, Lighthouse Performance 점수를 70에서 90으로 개선할 수 있었다.
단순히 이미지를 압축하는 것에 그치지 않고, 기존 업로드 흐름을 유지하면서 이미지 처리를 서버와 완전히 분리한 구조를 만든 것이 핵심이었다. 덕분에 기존 API와 클라이언트 코드 수정 없이 적용할 수 있었고, 업로드량이 늘어도 API 서버 부담이 커지지 않는 구조를 갖출 수 있었다.
결과적으로 사용자가 게시물을 탐색할 때 핵심 콘텐츠인 이미지를 지연 없이 확인할 수 있게 됐고, 처음 목표했던 이미지 노출 성능 개선을 달성할 수 있었다.
'문제 해결 & 구현 기록' 카테고리의 다른 글
| 이미지 최적화 파이프라인 구축기 (1) - 문제 진단과 방법 선택 (0) | 2026.03.23 |
|---|---|
| webpack 트리셰이킹이 안 된 진짜 이유: sideEffects 동명 옵션 혼동 (2) | 2026.03.06 |
| 이미지 로딩 속도 개선기 (webp, squoosh) (1) | 2025.12.24 |
| firebase 디지털 지문 SHA 이미 다른 프로젝트에 등록된 키 문제 해결 방법 (2) | 2024.12.10 |
| 안드로이드 스튜디오 iOS 시뮬레이터 실행 에러 해결기 (1) | 2024.12.02 |