서론
브라우저 주소창에 URL을 입력하면 어떤 일이 일어날까?
이 글에서는 Chrome DevTools Performance 패널로 직접 측정하며, 브라우저가 HTML을 받아오기까지의 네트워크 흐름을 살펴본다. TCP 연결 수립, TTFB, 캐시 정책 등 Network 막대 하나에 담긴 과정들을 하나씩 짚어볼 것이다.
Performance 패널로 확인한 이유는 단순한데, 평소에 성능을 세부적으로 측정하고 싶을 때 해당 도구를 사용하는데, 항상 보는 부분만 보고 다른 영역들은 뭘 의미하는걸까 궁금증을 갖고 있었다. 잘 모르니 단편적으로만 확인할 수 밖에 없었고, 그래서 더 잘 활용하고 싶은 니즈가 항상 있었다. 그래서 이번 기회에 조금 더 친해져보고자 사용하게 되었다.
참고로 학습하고 있는 입장이라 최대한 검토를 했으나 올바르지 않은 부분이 있을 수 있다. 계속 학습하면서 보완하고자한다. (혹시나 발견하면 편하게 댓글 부탁드립니다!)
*크롬 브라우저를 바탕으로 진행했다.
Performance 패널
Performance 패널이 무엇인지 간단히 먼저 짚고 가겠다.
Performance(성능) 패널은 웹 페이지가 로드되고 실행되는 동안의 속도와 동작을 분석하는 도구다. 자바스크립트 실행, 렌더링(HTML/CSS 파싱), 화면 업데이트 등 페이지 작동 과정에서 발생하는 병목 현상과 프레임 저하의 원인을 시각적으로 찾아낼 수 있다.

(1) Performance 패널은 개발자 도구(F12)를 키면 확인할 수 있다.
(2) 해당 버튼 클릭을 통해 측정을 시작할 수 있다. 첫 번째 버튼을 클릭하면 현 시점부터, 두 번째는 새로고침해서 새로운 페이지가 불러오는 시점부터 측정할 수 있다.
나는 사이트가 불러오는 과정을 확인하고 싶으므로 두 번째 버튼을 클릭해서 진행했다.
현재 프로젝트 파일 구성
프로젝트 폴더에는 간단하게 index.html 파일 하나만 있다. body 안에는 h1 태그 하나만 넣은 상태다.
<!doctype html>
<html lang="ko">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<h1>상추신</h1>
</body>
</html>
Performance 측정 결과

Network, Frames, Main 등 여러 영역이 보인다. ms 단위로 무언가가 기록되어 있고, 여러 막대가 표시되어 있다. 뭔가 되게 많은데 이 글에서는 Network 영역에 집중해서 살펴보고자 한다.
Main, Thread Pool, Frames 같은 나머지 영역은 추후 별도로 다뤄볼 예정이다. 마찬가지로 막대를 클릭하면 하단에 나오는 Bottom-up, Call tree, Event log 탭들은 JS 실행이나 파싱 작업의 내부 구조를 분석할 때 더 유용하므로 이 글에서는 다루지 않는다.
시간별 구간
시간(ms) 영역을 확인해보면 음수, 0, 양수 구간이 있는 걸 확인할 수 있다.
처음엔 '엥 index.html 요청하기도 전에 뭐가 실행되네..? 이게 가능한 일인가..?' 싶었는데, 자세히 보니 시간대가 음수 구간이었다.

음수 구간은 이전 페이지 로드 때 실행된 잔상이 표시된다. 나는 VSCode extension인 Live Server로 페이지를 열었는데, 해당 script가 실행된 것이었다.
💡 프로젝트 폴더엔 index.html만 있는데 어떻게 script가 실행된 것일까?
Live Server가 "파일이 바뀌면 자동으로 새로고침" 기능을 구현하기 위해, HTML을 서빙할 때 스크립트를 주입한다. 따라서 실제로 브라우저가 받은 HTML에는 body 끝에 WebSocket 연결 스크립트가 삽입되어 있다.

사진 기준, 시간 면에서 각 구간별 의미하는 걸 표현하면 다음과 같다.
| 구간 | 무슨 일 |
| 음수 ms | 이전 페이지 로드 때 실행된 잔상 (Live Server WebSocket 스크립트) |
| 0ms | 새로고침 발생 (기준점) |
| 약 2ms 지점 | index.html 네트워크 요청 시작 |
즉, 한 사이클의 시작 기준점을 0ms부터 보면 된다.

Network 영역
이제 본론으로, 맨 첫 번째 섹션으로 보이는 Network 영역을 확인해보고자 한다.

현재 Network 영역에는 index.html 막대 하나만 보인다.
이후 이어지는 보라색 점선은 클릭해도 아무런 정보가 안떠서 정확하진 않은데, Live Server의 WebSocket 연결(ws)로 추정된다. 이 점선은 이후에도 계속 이어지는데, 연결이 계속 열려있어서 점선으로 끝없이 이어지는걸로 추정된다.
실제 네트워크 패널에서 확인해보면 index.html 이후에 ws가 표시되는 것을 볼 수 있다.
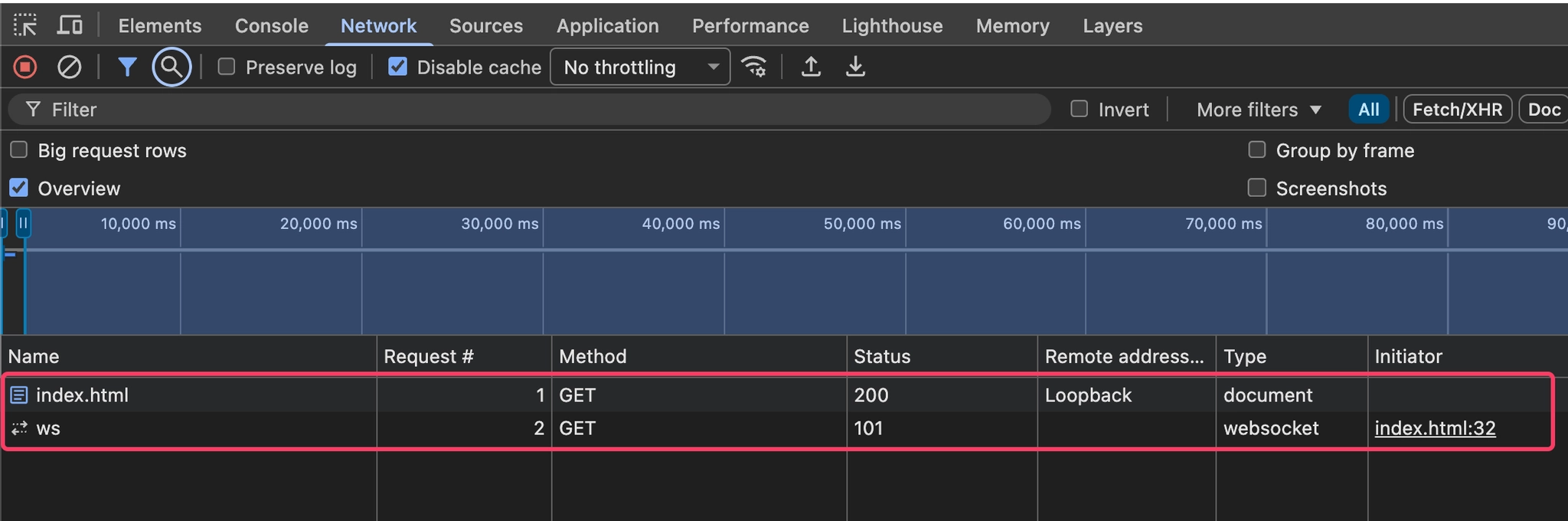
현재 프로젝트는 파일 하나만 있어서 네트워크 요청이 단순하지만, 네이버를 확인해보면 HTML 하나만 받는 게 아니라 CSS, JS, 이미지 등 수십 개의 리소스 요청이 동시에 이루어지는 걸 볼 수 있다.

Performance 하단에 있는 Summary 탭을 통해 세부 내용을 확인할 수 있다.
Summary는 다음과 같이 구성되어 있다. (1) 요청 파일(index.html), (2) 네트워크 메타 정보(Request method, Protocol 등), (3) 네트워크 흐름, (4) 관련 Insight를 확인할 수 있다.

이에 대해 차례대로 살펴보겠다.
요청 파일
말 그대로 요청한 파일이다. 클릭하면 어떤 파일을 요청했고, 어떤 응답이 왔는지 Source 패널로 이동되면서 확인할 수 있다

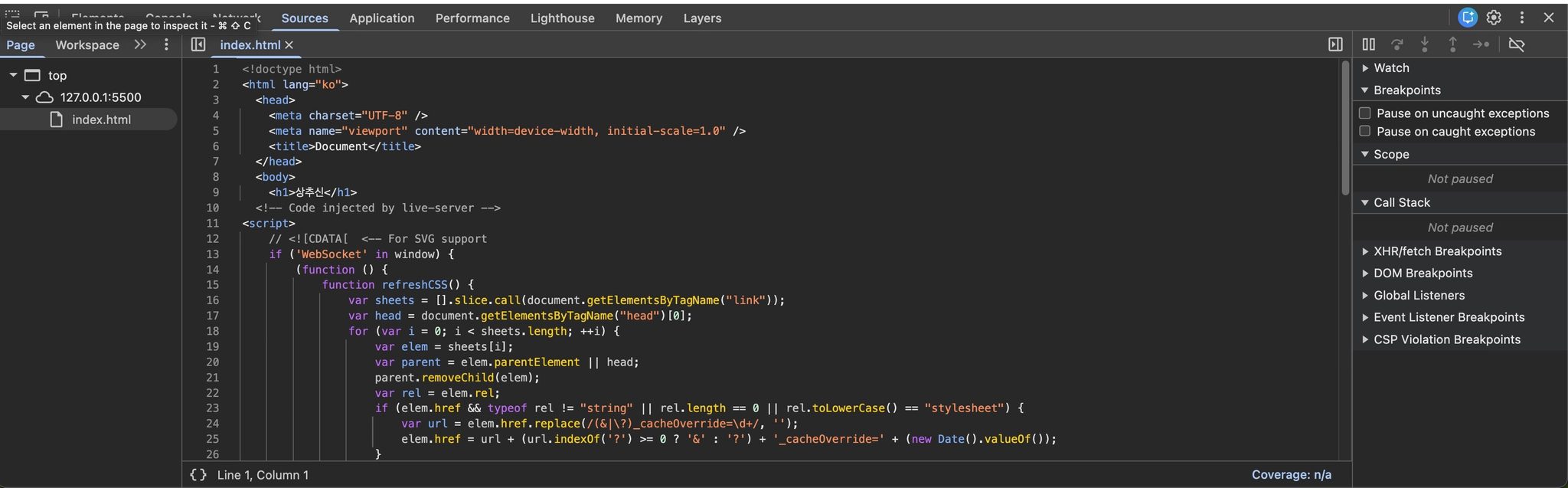
Network 메타 정보

1. Request method
브라우저가 서버에 요청을 보낼 때, 어떤 방식으로 요청하는지 의도를 나타낸다. 종류는 다음과 같다.
- GET: 서버에서 데이터를 가져오기만 하고, 서버 상태를 바꾸지 않는다. POST와 달리 *멱등성을 가진다.
- POST: 서버에 새 데이터를 보낼 때 쓴다. (ex. 폼 제출, 댓글 작성)
- PUT/PATCH: 기존 데이터를 수정할 때 사용한다. PUT은 전체 교체, PATCH는 일부 교체다.
- DELETE: 데이터를 삭제할 때 사용한다.
💡 멱등성이란?
멱등성은 "같은 작업을 여러 번 해도 결과가 달라지지 않는 성질"을 뜻한다.
GET 요청으로 네이버 메인 페이지를 1번 요청하든 100번 요청하든, 네이버 서버 안의 데이터는 전혀 바뀌지 않는다.
반면 POST는 멱등하지 않다. 댓글 작성 버튼을 100번 누르면 댓글이 100개 달리고, 결제 버튼을 100번 누르면 100번 결제가 된다. 요청할 때마다 서버 상태가 변하기 때문이다.
2. Protocol
브라우저와 서버가 대화하는 규칙이다. 종류는 다음과 같이 있다.
- HTTP/1.1: 요청 → 응답 → 요청 → 응답, 순서대로 한 번에 하나씩 처리한다. 앞 요청이 느리면 뒤 요청이 모두 밀리는 Head-of-line blocking 문제가 있다. 브라우저는 이를 우회하기 위해 *TCP 연결을 여러 개(보통 6개) 동시에 열기도 하지만, 이는 연결마다 수립 비용이 발생하는 문제가 있다.
- HTTP/2: 하나의 TCP 연결에서 여러 요청을 동시에 처리하는 멀티플렉싱을 도입했다. 스트림(Stream)마다 번호를 붙여 응답이 뒤섞여 도착해도 올바르게 조립할 수 있다. 다만 TCP 레벨에서는 여전히 패킷 하나가 손실되면 전체 스트림이 멈추는 문제가 남아 있다.
- HTTP/3: 아예 TCP 대신 *UDP 기반의 *QUIC 프로토콜을 사용한다. 스트림 단위로 독립적으로 재전송하기 때문에, 한 스트림에서 패킷이 손실돼도 나머지는 영향 없이 계속 진행된다. 연결 수립도 빠르다. TCP는 3-way handshake로 1 *RTT가 필요하고 HTTPS면 *TLS까지 더해 2~3 RTT가 걸리는 반면, QUIC은 최초 연결도 1 RTT, 재접속 시 0 RTT로 처리한다.

💡 용어 사전 - RTT, TLS, TCP, UDP, QUIC
- RTT (Round Trip Time): 신호가 출발해서 돌아오기까지 걸리는 왕복 시간이다. 브라우저가 서버에 신호를 보내고 응답을 받을 때까지의 시간이다. 서버가 멀수록 RTT가 길어진다.

- TLS (Transport Layer Security): 데이터를 암호화해서 주고받기 위한 보안 프로토콜이다. HTTPS의 S가 바로 TLS 덕분이다. TCP 연결을 맺은 뒤 TLS 핸드셰이크를 추가로 해야 해서 연결 수립에 RTT가 더 필요하다.
- TCP (Transmission Control Protocol): 인터넷에서 데이터를 안정적으로 주고받기 위한 전송 규칙이다. 패킷이 순서대로, 빠짐없이 도착하도록 보장한다. 대신 패킷이 하나라도 손실되면 재전송을 기다리느라 전체가 멈춘다.
- UDP (User Datagram Protocol): TCP와 달리 패킷 순서나 도착 여부를 보장하지 않는다. 신뢰성은 낮지만 속도가 빠르고 유연하다.
- QUIC: 구글이 만들고 HTTP/3의 기반이 된 전송 프로토콜이다. UDP 위에서 동작하면서 TCP처럼 신뢰성 있는 전송을 제공하되, 스트림 단위로 독립적으로 처리한다. 암호화(TLS)도 기본으로 내장돼 있어서 연결 수립이 빠르다.

현재 프로젝트는 http/1.1이다. localhost라 물리적 거리가 0이므로 충분히 빠르고 사용하기 괜찮다. 실제 배포 서버는 수십~수백ms 네트워크 지연이 발생할 수 있으므로 http/2 멀티플렉싱이 거의 필수라고 한다.
실제 naver.com에서 Performance를 확인해보니 Protocol h2가 찍혀있는 걸 확인할 수 있다.

3. Priority
브라우저가 리소스를 받는 순서를 결정하는 값이다.
브라우저는 한 페이지를 로드할 때 수십 개의 요청을 동시에 보내는데, 다 똑같이 급한 건 아니니 순서를 지정할 수 있다. 브라우저가 이 Priority를 보고 어떤 요청부터 처리할지 자동으로 판단한다.
HTML은 존재하지 않으면 파싱 자체를 시작 못 하므로 보통 Highest다. CSS는 High, JS는 상황에 따라 High~Low, 화면 아래쪽 이미지는 Low로 설정할 수 있다.
💡 Priority 설정 방법
1. fetchpriority 속성
fetchpriority="high"를 쓰는 대표적인 경우는 LCP(Largest Contentful Paint) 요소다.
화면에서 가장 크게 보이는 이미지나 텍스트가 빨리 로드돼야 사용자가 빠르다고 느끼기 때문이다.
<!-- 높은 우선순위 -->
<img src="hero.jpg" fetchpriority="high">
<!-- 낮은 우선순위 -->
<script src="analytics.js" fetchpriority="low"></script>
<!-- 브라우저 기본값 사용 -->
<img src="thumbnail.jpg" fetchpriority="auto">
2. <link rel="preload">
브라우저에게 "이 리소스 곧 쓸 거니까 미리 높은 우선순위로 받아놔"라고 보내는 힌트다.
3. defer, async 속성
이 속성들도 간접적으로 Priority에 영향을 준다. defer를 붙이면 JS 요청 우선순위가 낮아지고, 파싱을 블로킹하지 않는다.
4. MIME type
현재 보내는 요청의 타입이다. 브라우저는 이 값을 보고 어떻게 처리할지 결정한다.
예를 들어, text/html이면 DOM 파싱을 시작하고, text/css면 CSSOM을 만들고, application/javascript면 JS 엔진에 넘긴다.
만약 이 값이 없거나 잘못됐으면 브라우저가 파일 내용을 보고 추측해야 한다(스니핑). 추측이 틀리면 처리를 다시 해야 하는 비용이 생긴다.
5. Encoded / Decoded
Encoded는 서버가 HTML을 압축해서 보낸 용량이고, Decoded는 브라우저가 받아서 풀은 용량이다.
지금은 파일이 워낙 작아서 압축 효과가 거의 없지만, 네이버를 예시로 보면 259kB → 39.5kB로 약 6.5배 압축된 것을 확인할 수 있다. 파일이 클수록 gzip 압축의 효과가 극적으로 나타난다.
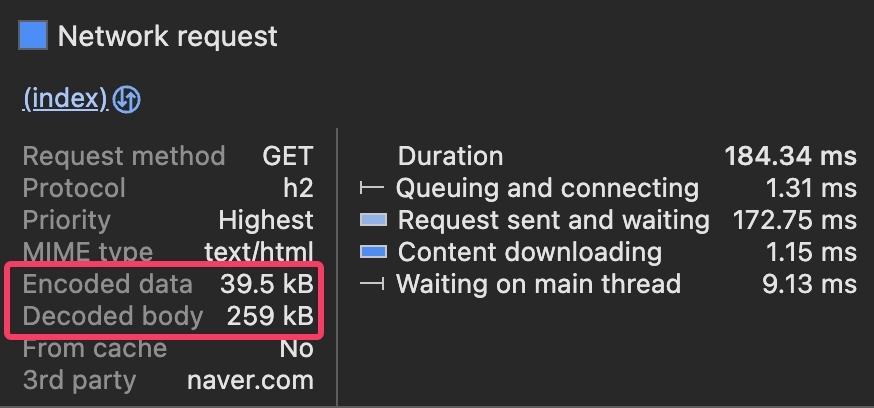
6. From cache
캐시를 통해서 왔냐 여부다. 현재 프로젝트는 No로 되어 있는데, 이는 캐시를 쓰지 않고 서버에서 직접 받아왔다는 뜻이다. Disable cache를 체크해두거나 시크릿 모드일 때, 사이트에 최초 접속 시 No로 된다.
만약 캐시가 있었다면 From cache: memory cache 또는 disk cache라고 찍히고, Duration이 짧게 나온다. 서버에 요청 자체를 안 보내고 로컬에서 바로 꺼내오기 때문이다.
네이버를 통해 확인해봤는데, 시크릿 모드가 아니고 Disable cache도 꺼놨는데, 새로고침을 계속해도 from cache가 No로 떴다. 이는 캐시 정책(Cache-Control 헤더) 때문이었다. 캐시를 쓸지 말지는 브라우저가 일방적으로 결정하는 게 아니라, 서버가 응답 헤더에 지시를 내린다.
Cache-Control: no-cache # 매번 서버에 확인하고 써라
Cache-Control: no-store # 아예 캐시하지 마라
Cache-Control: max-age=3600 # 3600초 동안 캐시 써도 된다
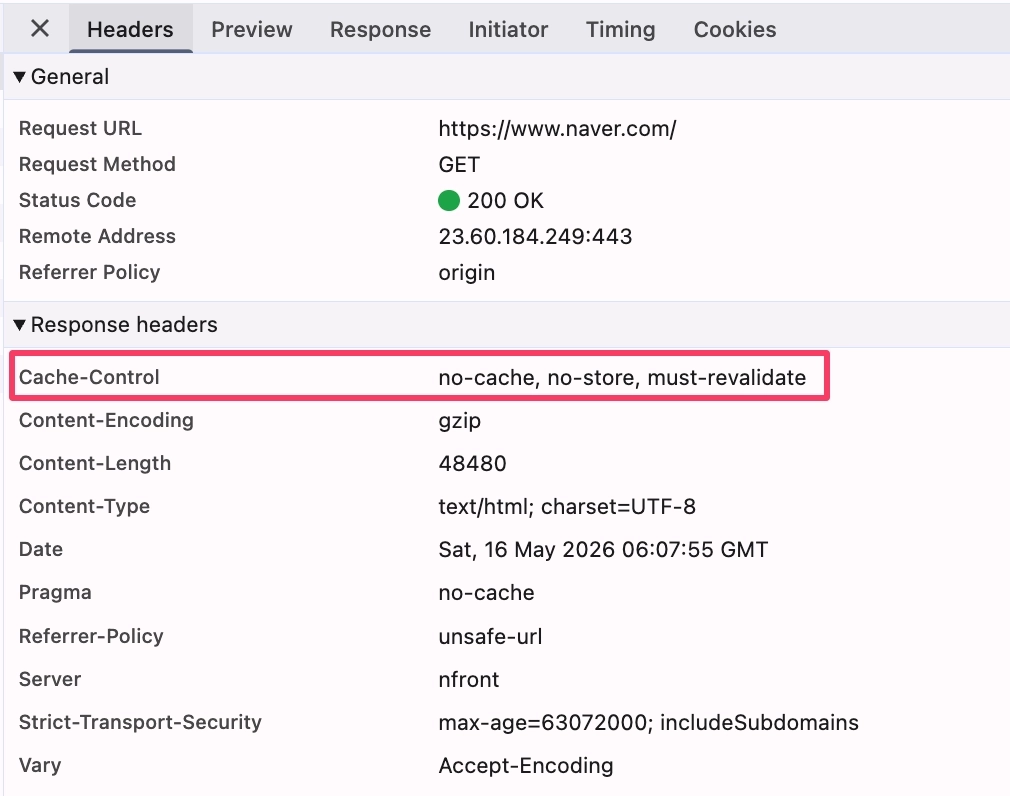
Network 탭에서 네이버 메인 HTML 요청을 클릭하고 Response Headers를 보면 Cache-Control: no-cache, no-store, must-revalidate가 찍혀 있다. 뉴스, 실시간 검색어 등이 계속 바뀌는 페이지라 항상 서버에서 새로 받아오도록 강제한 것이다.
추가로 Pragma: no-cache도 함께 찍혀 있는데, 이는 HTTP/1.0 시절의 캐시 제어 방식이다. 현대 브라우저는 Cache-Control만 봐도 충분하지만, 오래된 프록시 서버 환경까지 대비해서 네이버 같은 대형 서비스는 이중으로 보내는 것이다.
7. 3rd party
이 요청을 보낸 출처 도메인(origin)을 뜻한다. naver.com에서는 naver.com이 찍히고, 외부 서비스에서 발생한 요청이라면 그쪽 도메인이 찍힌다.
Network 흐름

네트워크 막대의 각 영역이 무엇을 뜻하는지, 몇 ms가 소요되었는지를 Summary에서 확인해서 표시해보았다. 이에 대해 순서대로 알아보자.

1. Queuing and connecting
브라우저가 "index.html 달라"고 요청하기 전, TCP 연결을 수립하는 준비 구간이다. TCP 3-way handshake가 이 구간에서 일어난다. 브라우저와 서버가 SYN → SYN-ACK → ACK 세 번의 신호를 주고받으며 "연결됐다"는 상태를 확인한 뒤에야 실제 요청을 보낼 수 있다.
지금은 localhost 서버인데, 실제 서버면 DNS 조회까지 여기 포함된다. localhost라 1~2ms로 짧게 끝났지만, 실제 배포 서버라면 물리적 거리에 따른 RTT(왕복 시간)만큼 이 구간이 길어진다.
단, 대형 서비스들은 CDN으로 물리적 거리를 줄이고, 브라우저가 TCP 연결을 재사용하거나 preconnect로 미리 연결을 맺어두는 등의 최적화 덕분에 실제 체감은 훨씬 짧은 경우가 많다고 한다. 실제 서버 환경에서 Queuing and connecting 구간이 길게 찍힌다면, 이 handshake 비용이 주요 원인 중 하나라 할 수 있다.

2. Request sent and Waiting
요청을 서버에 전송하고, 서버가 응답의 첫 번째 바이트를 돌려줄 때까지 기다리는 구간이다. 이걸 TTFB(Time To First Byte)라고 한다.
💡 왜 첫 번째 바이트인가?
첫 번째 바이트는 서버가 요청을 받고 나서 "처리를 시작했고, 이제 응답을 보낼게"라는 신호를 뜻한다.
첫 번째 바이트가 도착하기 전까지는 브라우저 입장에서 서버가 뭘 하는지 전혀 알 수 없다. 처리 중인지, 막혀있는지, 죽었는지조차 모르는 것이다.전체 다운로드 시간은 파일 크기에 따라 달라지니까, 서버 처리 속도만 순수하게 측정하려면 "첫 바이트가 언제 왔냐"를 보는 게 가장 정확하다. 그래서 TTFB는 서버 성능의 순수한 지표로 쓰인다.
브라우저 요청 도착
↓
서버: DB에서 사용자 데이터 조회
↓
서버: 조회 결과로 HTML 생성
↓
서버: 첫 번째 바이트 전송 ← 이 시점이 TTFB
↓
나머지 바이트들 전송
DB 조회가 느리거나, 서버 코드가 무거운 계산을 하거나, 서버 자체가 멀리 있으면(물리적 거리 = 네트워크 지연) TTFB가 길어지는 것이다. localhost라서 6ms로 짧게 끝났지만, 실제 배포된 서버라면 수십~수백ms가 나올 수 있고, 이게 느리면 아무리 프론트엔드를 최적화해도 체감 속도가 느려지는 것이다.
택배 비유로 생각해보면, 온라인 쇼핑몰에서 주문 후 "배송 시작" 문자를 받기까지 걸리는 시간이 TTFB다. 이 문자를 받기 전까지는 창고에서 상품을 찾고 있는지, 포장 중인지, 재고가 없어서 고민 중인지 알 수 없다. 물건이 집에 도착하는 시간(전체 다운로드)과는 별개로, 이 "배송 시작" 문자를 받기까지 얼마나 걸리느냐가 TTFB다.
브라우저가 index.html을 요청하면, 서버는 파일을 한 번에 통째로 보내는 게 아니다. 데이터를 잘게 쪼갠 패킷(packet) 단위로 나눠서 보낸다. 그래서 2KB짜리 HTML도 실제로는 여러 패킷으로 분할돼서 도착한다.
3. Content downloading
첫 바이트가 도착했고, 실제 HTML 내용을 내려받는 구간이다. 파일 크기가 클수록 이 구간이 길어진다.
4. Waiting on main thread
HTML 다운로드가 완료됐는데도 곧바로 파싱이 시작되지 않는 구간이다. 정확한 원인은 타임라인만으로 특정하기 어렵지만, OS 스케줄링 지연으로 추정된다. Main 스레드가 이 요청을 처리할 차례가 될 때까지 대기하는 것이다.
5. 영역 끝
막대의 실선이 끝나는 시점으로, Main 스레드가 드디어 이 요청을 처리하기 시작해서 Parse HTML이 시작되는 지점이다. 이후 보이는 점선은 Live Server의 WebSocket 연결 같은 Critical Path와 무관한 부가 요청이다. (Critical Path은 아래 Insight에서 자세히 다룬다.)
Network Insight
이 부분은 Performance 패널이 네트워크 요청을 어떻게 진단하는지를 살펴보는 Insight 섹션이다. 좀 세부적인 내용인 것 같아, 관심 있는 분만 읽어도 좋을 것 같다. 나는 학습 차원에서 더 살펴보았다.

1. Network dependency tree

(1) "critical request chain을 줄여라"라고 말하고 있다.
브라우저가 페이지를 처음 화면에 그리려면 반드시 먼저 받아야 하는 리소스들이 있는데, 이걸 Critical Path라고 한다. 이 인사이트는 현재 Critical Path 구조가 어떻게 생겼는지를 항상 보여주는 정보성 패널로 보인다. (공식 문서에서는 "critical request가 페이지 초반에 발견되지 않을 때만 fail로 표시된다"고 나와 있어, 문제가 있을 때만 경고하는 게 아니라 항상 표시되는 것으로 보인다.)
지금 나의 프로젝트는 index.html 하나뿐이라 체인이 단순하다. Max critical path latency: 16.60ms는 그냥 index.html 받는 데 걸린 시간이다. 실제 프로젝트라면 다음과 같은 체인이 생긴다.
index.html 수신
└── style.css 발견 → 요청 → 수신 (렌더 블로킹!)
└── @import로 또 다른 CSS 발견 → 요청 → 수신
이렇게 A를 받아야 B를 발견하고, B를 받아야 C를 발견하는 구조가 "chained critical requests"다. 체인이 길어질수록 첫 화면이 늦게 그려진다.
여기서 CSS를 <head> 맨 위에 넣고, JS는 defer를 쓰는 이유를 이해할 수 있다. CSS는 화면을 그리기 위해 반드시 필요한 Critical Path 리소스라서, HTML 파싱이 시작되자마자 최대한 빨리 요청을 보낼 수 있도록 <head> 상단에 둔다. JS는 반대로 <head>에 그냥 넣으면 파싱이 중단된다(파서 블로킹). defer를 붙이면 JS 다운로드는 파싱과 병렬로 진행하되 실행은 파싱이 완료된 후로 미뤄서, Critical Path에서 JS를 사실상 제거하는 효과가 생긴다.
(2) "2 others"
브라우저는 index.html 하나만 요청하는 게 아니다. 페이지를 로드할 때 브라우저가 자동으로 보내는 요청들이 있다.

네트워크 탭을 확인하면 현재 페이지에는 index.html과 ws(WebSocket) 두 가지 요청이 찍혀 있다. index.html은 Critical Path의 시작점이고, ws는 Live Server가 주입한 WebSocket 연결로 Critical Path에 영향을 주지 않아 "others"로 묶인다. (나머지 한개는 무엇인지 확인하지 못했다..)
(3) Preconnect
preconnect는 브라우저에게 "이 서버랑 나중에 연결할 거니까 미리 TCP 연결 맺어놔"라고 힌트를 주는 HTML 태그다.
<link rel="preconnect" href="https://fonts.googleapis.com">지금 내 페이지는 외부 서버에 연결하는 게 없으니 "no origins were preconnected"라고 나온 거고, 추천할 것도 없으니 "No additional candidates"라고 나온 것이다.
2. Document request latency
브라우저가 서버에 첫 번째 요청을 보내고 응답을 받기까지의 지연 시간을 분석하는 인사이트다.
앞서 Network 막대에서 봤던 Queuing → Request sent & waiting → Content downloading 흐름의 전체 품질을 진단해준다. 세 항목 모두 초록색 체크로 통과됐다.

(1) Avoids redirects는 Queuing 구간과 연결된다. 예를 들어 http://sanghee01.tistory.com/에 접속했는데 서버가 "아, 그건 https://sanghee01.tistory.com/으로 가세요"라고 301 응답을 돌려주면, 브라우저는 새 주소로 요청을 처음부터 다시 보내야 한다. Queuing부터 전부 다시 시작하는 거라 시간이 두 배로 걸린다. 지금은 localhost를 직접 접속하니까 리다이렉트가 없어서 체크로 표시되었다.
(2) Server responds quickly (observed 6ms)는 TTFB를 뜻한다. Request sent and waiting 구간이 6ms였다는 거고, 서버가 빠르게 응답했다는 뜻이다. 실제 서비스라면 서버가 DB 조회나 렌더링을 해야 해서 이 시간이 길어질 수 있다.
(3) Applies text compression은 Content downloading 구간과 연결된다. 서버가 HTML을 그냥 보내는 게 아니라 gzip이나 brotli로 압축해서 보내면 파일 크기가 줄어서 다운로드 시간이 짧아진다. Live Server가 기본적으로 압축을 적용해주고 있어서 체크 표시 되었다.
3. Declare a character encoding
파싱 세부 동작에서, 브라우저가 HTML을 받으면 바이트를 문자로 변환하는 단계가 있다. 이때 브라우저는 "이 바이트들을 어떤 문자 인코딩으로 해석해야 하나"를 알아야 한다. 그 규칙이 바로 문자 인코딩(Character Encoding)이다.
예를 들어 EC 95 88이라는 바이트 세 개가 있을 때, 이게 UTF-8 규칙으로 읽으면 "안"이 되고, 다른 인코딩으로 읽으면 전혀 다른 문자가 되거나 깨진다. 즉 인코딩을 모르면 바이트를 올바른 문자로 변환할 수 없다.
브라우저에게 인코딩을 알려주는 방법은 두 가지가 있다.
- 첫째는 HTTP 응답 헤더에 선언하는 방법이다. 서버가 HTML 파일을 보낼 때 Content-Type: text/html; charset=UTF-8을 같이 보내면, 브라우저는 HTML 바이트를 받기 시작하는 순간부터 인코딩을 알 수 있다. 가장 빠른 방법이다.
- 둘째는 HTML 안의 <meta charset> 태그로 선언하는 방법이다. HTTP 헤더가 없을 때를 대비한 백업이다. 단, 이 태그는 반드시 첫 1024바이트 안에 있어야 한다. 브라우저가 인코딩을 모른 채로 너무 많은 바이트를 읽어버리면 이미 잘못된 해석이 시작되기 때문이다..
이 두 가지를 각각 체크하는 것이 해당 인사이트 패널이다.

(1) Declares charset in HTTP header ✅ : Live Server가 Content-Type: text/html; charset=UTF-8를 자동으로 붙여줘서 초록 체크가 떴다.
(2) Could not determine meta charset declaration from trace ❌ : 실제로는 <meta charset="UTF-8" />가 있는데 없다고 표시되고 있다. Live Server가 body 끝에 스크립트를 주입하면서 파싱 trace가 복잡해졌을 가능성이 있다. 하지만 이미 첫 번째 체크(HTTP 헤더)가 통과됐으니, 브라우저는 이미 인코딩을 알고 있으므로 큰 문제는 없다. 애초에 해당 meta 태그는 HTTP 헤더가 없을 때를 대비한 백업이기 때문이다.
💡 왜 인코딩 선언이 중요한가?
만약 인코딩 선언이 없으면, 브라우저는 바이트를 일단 읽으면서 추측을 한다. 이걸 "인코딩 스니핑"이라고 한다.
그런데 추측이 틀리면 파싱을 처음부터 다시 해야 한다. 이 경우 파싱이 멈추고 재시작되는 지연이 생긴다. 그래서 공식문서가 "첫 1024바이트 안에 선언하라"고 강조하는 것이다. 브라우저가 추측할 틈도 없이 바로 알 수 있도록 말이다.
마무리
지금까지 Performance 패널 Network 막대 하나를 직접 확인해보면서, 브라우저가 HTML 파일을 받기까지 어떤 일이 일어나는지를 확인해봤다. 이 과정에서 이 단순한 막대 하나에 여러가지 정보를 확인할 수 있음을 확인할 수 있었다.
단순해 보이는 index.html 하나를 받는 과정에서도 TCP 연결 수립, TTFB, 압축과 해제, 캐시 정책, Main 스레드 스케줄링 대기까지 생각보다 많은 일들이 일어나고 있었다. 이 과정이 실제로 얼마나 걸리는지를 ms 단위로 볼 수 있으니 훨씬 와닿았다.
네이버랑도 비교를 진행했다. 단순한 HTML 파일 하나와는 차원이 달랐다. 수십 개의 요청이 동시에 쏟아지는데, 우선순위도 다르고 캐시 정책도 제각각이었다. 우리가 그냥 당연하게 "네이버 들어간다"고 생각하는 그 순간에 이런 일들이 벌어지고 있었던 것이다.
여기까지가 브라우저가 HTML을 받아오는 과정이다. 이제 이 HTML을 파싱해서 DOM을 만들고, CSS를 처리해서 화면에 그려나가는 일이 시작된다. 그 과정, 즉 DOM 생성, 렌더 트리, Layout, Paint, Composite 같은 렌더링 파이프라인은 별도로 다뤄볼 예정이다.
'CS > Network' 카테고리의 다른 글
| 컴퓨터 네트워크 - 네트워크란?, 패킷, LAN, WAN (1) | 2024.03.30 |
|---|---|
| 네트워크 기초 지식 (0) | 2023.04.06 |